Cloudera SQL Stream Builder (SSB) Released!

CSA 1.3.0 is now available with Apache Flink 1.12 and SQL Stream Builder! Check out this white paper for some details. You can get full details on the Stream Processing and Analytics available from Cloudera here.
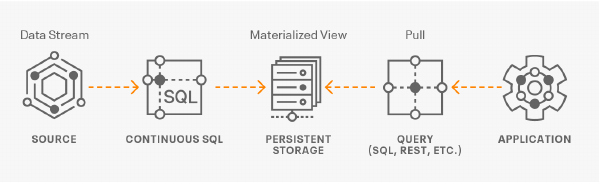

References:
- https://docs.cloudera.com/csa/1.3.0/ssb-using-ssb/topics/csa-ssb-using-virtual-tables.html
- https://docs.cloudera.com/csa/1.3.0/ssb-overview/topics/csa-ssb-intro.html
- https://docs.cloudera.com/csa/1.3.0/ssb-overview/topics/csa-ssb-key-features.html
- https://docs.cloudera.com/csa/1.3.0/ssb-overview/topics/csa-ssb-architecture.html
- https://docs.cloudera.com/csa/1.3.0/ssb-quickstart/topics/csa-ssb-quickstart.html
- https://docs.cloudera.com/csa/1.3.0/ssb-using-ssb/topics/csa-ssb-adding-kafka-data-source.html
- https://docs.cloudera.com/csa/1.3.0/ssb-using-ssb/topics/csa-ssb-using-virtual-tables.html
- https://docs.cloudera.com/csa/1.3.0/ssb-using-ssb/topics/csa-ssb-creating-virtual-kafka-source.html
- https://docs.cloudera.com/csa/1.3.0/ssb-using-ssb/topics/csa-ssb-creating-virtual-kafka-sink.html
- https://docs.cloudera.com/csa/1.3.0/ssb-using-ssb/topics/csa-ssb-creating-virtual-webhook-sink.html
- https://docs.cloudera.com/csa/1.3.0/ssb-using-ssb/topics/csa-ssb-managing-time.html
- https://docs.cloudera.com/csa/1.3.0/ssb-job-lifecycle/topics/csa-ssb-running-job-process.html
- https://docs.cloudera.com/csa/1.3.0/ssb-job-lifecycle/topics/csa-ssb-job-management.html
- https://docs.cloudera.com/csa/1.3.0/ssb-job-lifecycle/topics/csa-ssb-sampling-data.html
- https://docs.cloudera.com/csa/1.3.0/ssb-job-lifecycle/topics/csa-ssb-advanced-job-management.html
- https://docs.cloudera.com/csa/1.3.0/ssb-using-mv/topics/csa-ssb-using-mvs.html
- https://www.cloudera.com/content/www/en-us/about/events/webinars/cloudera-sqlstream-builder.html
- https://www.cloudera.com/about/events/webinars/demo-jam-live-expands-nifi-kafka-flink.html
- https://www.cloudera.com/about/events/virtual-events/cloudera-emerging-technology-day.html

Example Queries:
SELECT location, max(temp_f) as max_temp_f, avg(temp_f) as avg_temp_f,
min(temp_f) as min_temp_f
min(temp_f) as min_temp_f
FROM weather2
GROUP BY location
SELECT HOP_END(eventTimestamp, INTERVAL '1' SECOND, INTERVAL '30' SECOND) as windowEnd,
count(`close`) as closeCount,
count(`close`) as closeCount,
sum(cast(`close` as float)) as closeSum, avg(cast(`close` as float)) as closeAverage,
min(`close`) as closeMin,
min(`close`) as closeMin,
max(`close`) as closeMax,
sum(case when `close` > 14 then 1 else 0 end) as stockGreaterThan14
FROM stocksraw
WHERE symbol = 'CLDR'
GROUP BY HOP(eventTimestamp, INTERVAL '1' SECOND, INTERVAL '30' SECOND)
WHERE symbol = 'CLDR'
GROUP BY HOP(eventTimestamp, INTERVAL '1' SECOND, INTERVAL '30' SECOND)
SELECT scada2.uuid, scada2.systemtime, scada2.temperaturef, scada2.pressure, scada2.humidity, scada2.lux, scada2.proximity,
scada2.oxidising,scada2.reducing , scada2.nh3, scada2.gasko,energy2.`current`,
energy2.voltage,energy2.`power`,energy2.`total`,energy2.fanstatus
FROM energy2 JOIN scada2 ON energy2.systemtime = scada2.systemtime
SELECT symbol, uuid, ts, dt, `open`, `close`, high, volume, `low`, `datetime`, 'new-high' message,
'nh' alertcode, CAST(CURRENT_TIMESTAMP AS BIGINT) alerttime
FROM stocksraw st
WHERE symbol is not null
AND symbol <> 'null'
AND trim(symbol) <> '' and
CAST(`close` as DOUBLE) >
(SELECT MAX(CAST(`close` as DOUBLE))
FROM stocksraw s
FROM stocksraw s
WHERE s.symbol = st.symbol);
SELECT *
FROM statusevents
WHERE lower(description) like '%fail%'
SELECT
sensor_id as device_id,
HOP_END(sensor_ts, INTERVAL '1' SECOND, INTERVAL '30' SECOND) as windowEnd,
count(*) as sensorCount,
sum(sensor_6) as sensorSum,
avg(cast(sensor_6 as float)) as sensorAverage,
min(sensor_6) as sensorMin,
max(sensor_6) as sensorMax,
sum(case when sensor_6 > 70 then 1 else 0 end) as sensorGreaterThan60
FROM iot_enriched_source
GROUP BY
sensor_id,
HOP(sensor_ts, INTERVAL '1' SECOND, INTERVAL '30' SECOND)
SELECT title, description, pubDate, `point`, `uuid`, `ts`, eventTimestamp
FROM transcomevents
Source Code:
- https://github.com/tspannhw/CloudDemo2021
- https://github.com/tspannhw/StreamingSQLDemos
- https://github.com/tspannhw/SmartTransit
Example SQL Stream Builder Run
We login then build our Kafka data source(s), unless they were predefined.
Next we build a few virtual table sources for Kafka topics we are going to read from. If they are JSON we can let SSB determine the schema for us. Or we can connect to the Cloudera Schema Registry for it to determine the schema for AVRO data.
We can then define virtual table syncs to Kafka or webhooks.
We then run a SQL query with some easy to determine parameters and if we like the results we can create a materialized view.

















































